Open-source OpenClaw gives me the runtime: agents, tools, sessions, messaging surfaces, cron, browser access, filesystem access, and a way to run a personal AI system on my own machine.
My instance adds the operating layer above that substrate.
That layer turns the framework into a working system for my own life and work: Telegram topic routing, owner files, memory discipline, execution lanes, recurring jobs, and a split between front-door skills and lazy-loaded capabilities.
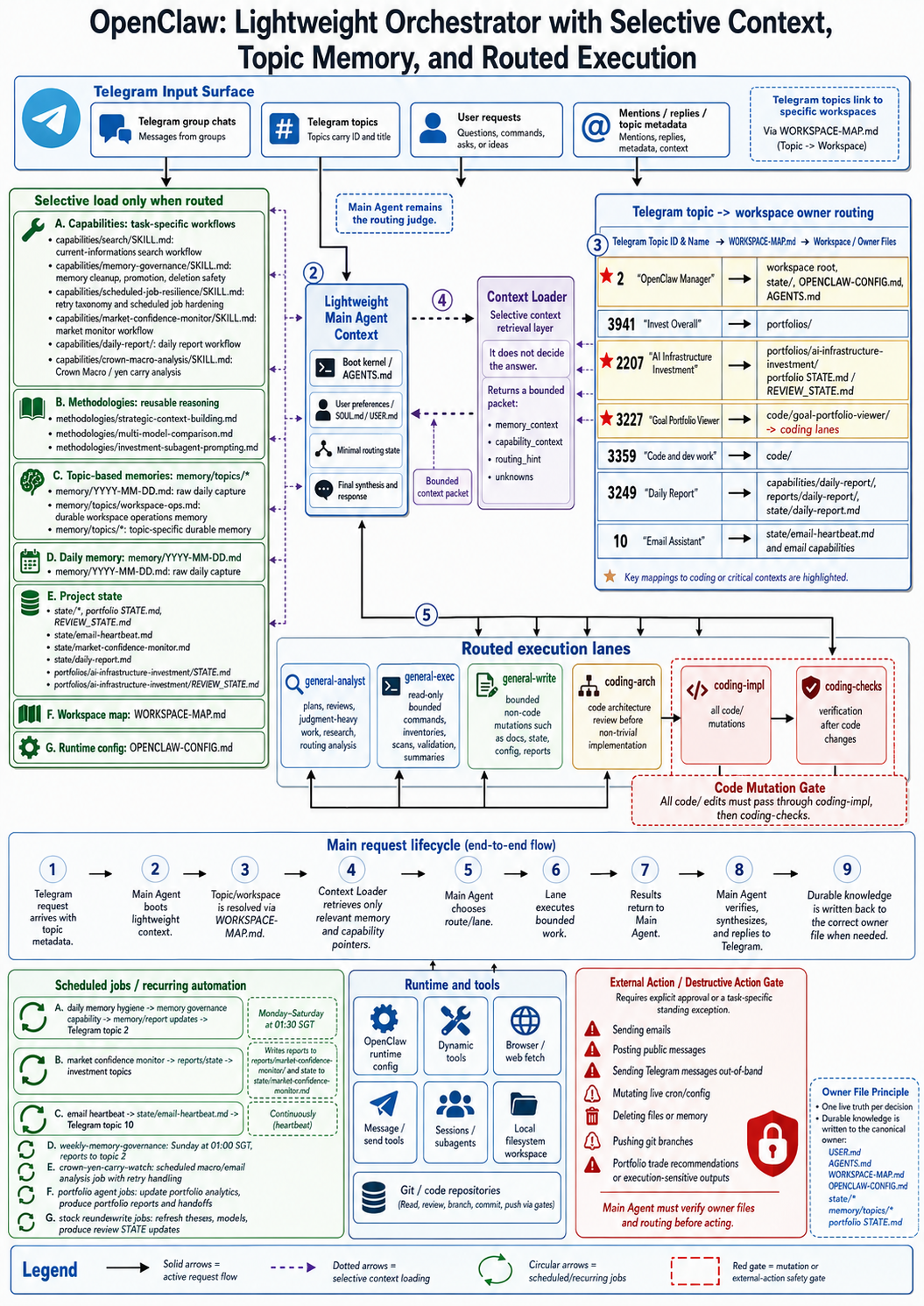
The runtime architecture of my OpenClaw instance: a lightweight main agent, selective context loading, topic-based routing, execution lanes, recurring jobs, and safety gates.
The skills-to-capabilities split became the central architectural lesson.
At first, I treated skills as the natural home for every repeatable procedure. Search skill. Email skill. Memory skill. Portfolio skill. Review skill. Writing skill. Travel skill. Deployment skill. Cron skill.
That worked for a while.
Then the skills catalog became too large. The runtime-visible instruction surface started flooding the context. The assistant could see too many possible procedures at once, which made the system slower, noisier, and more likely to pick up the wrong pattern.
It also created context rot.
Old instructions stayed visible after the system had moved on. Stale routing names, retired workflow assumptions, and older helper patterns could sit beside newer ones. The model then had to infer which version of the system was real. That is a poor use of intelligence. The assistant should spend its reasoning budget on the user’s problem, rather than on archaeology across stale instructions.
So I changed the architecture. OpenClaw remained the open-source runtime. My instance grew its own control plane on top.
The Operating Layer
The open-source project gives me powerful primitives.
A personal AI system still needs local answers: where a branding request lives, which portfolio file owns current state, which agent can mutate code, when a Telegram reply should stay in the same topic, which facts are durable, which memories are raw capture, which actions need approval, which workflows can run on cron, and which outputs require verification.
Those are instance questions.
My architecture is built around that distinction. The upstream runtime supplies the machine. My workspace supplies the constitution, routing map, memory owners, capability registry, execution lanes, and safety gates.
That separation keeps the system from confusing available tool access with permission to act.
Telegram Became a Routing Surface
I use Telegram topics as the front door.
That sounds simple, and it changes the architecture. A message arrives with a group, topic ID, reply chain, sender, and surface metadata. My instance uses that metadata before deciding what the request means.
The Branding topic routes to the branding workspace and Hugo site. Investment topics route to portfolio owners. Code topics route into the code workspace and trigger stricter mutation gates. The OpenClaw Manager topic routes to runtime state, config, memory governance, cron, and operational files.
The open-source runtime can deliver the message. My WORKSPACE-MAP.md gives that message local meaning: topic 56 means personal branding, topic 2207 means AI Infrastructure Investment, topic 3227 means Goal Portfolio Viewer, and topic 2 means OpenClaw Manager.
That map is part of the execution path.
It prevents the assistant from treating every sentence as a free-floating prompt. In a real workspace, “review this”, “move those commits”, or “do this on a new branch” only makes sense after the system knows which workspace owns the request.
The chat surface becomes an operating surface once the routing is explicit.
Owner Files Are My Control Plane
The core of my instance is a set of owner files.
AGENTS.md owns workspace gates and routing rules. USER.md owns my preferences and safety boundaries. SOUL.md owns the assistant’s voice and posture. WORKSPACE-MAP.md owns topic routing. OPENCLAW-CONFIG.md points to runtime configuration. state/* owns live operational state. memory/topics/* owns durable topic memory. Portfolio STATE.md and REVIEW_STATE.md files own portfolio substance.
This is plain, practical infrastructure.
Owner files prevent the assistant from inferring authority from chat history. Chat history contains experiments, abandoned ideas, stale instructions, and one-off context that should stay local to the moment.
The rule is simple: one live truth per decision.
If a rule matters, it belongs in the file that owns it. If a fact is raw capture, it stays in daily memory. If a piece of state changes often, it lives in state/* or a project state file. If a capability defines a workflow, the workflow lives in that capability file.
This gives the assistant an authority hierarchy. It also makes behavior inspectable: I can trace a decision back to the file that owns it.
That is one of the biggest differences between a chat assistant and an operating layer.
Context Flooding and Context Rot
The first version of the system leaned too heavily on skills.
That was a reasonable starting point. Skills are useful for repeatable work. The problem emerged when every procedure became runtime-visible.
The visible catalog grew into a second prompt. The assistant started each turn with too many nearby affordances. The model was being shaped by instructions for tasks that had nothing to do with the current request.
Context flooding became an attention problem as much as a token problem.
The assistant could become over-aware of irrelevant workflows. It could select a nearby but wrong skill. It could spend effort reconciling instruction surfaces before doing the actual task. Riskier procedures also stayed visible in contexts where they should rarely appear.
Context rot made this worse.
As the system evolved, older names and assumptions lingered. The model then had to choose between live rules, stale rules, compatibility shims, and old summaries. More context made the system look more complete while quietly making it less disciplined.
That was the architectural mistake.
Skills Became Front-Door Controls
The fix was to shrink the runtime-visible skills surface.
In my current architecture, skills/ is reserved for front-door controls:
memory-contextcapability-contextroute-workreview-router
These controls help the main agent decide what to load, where to route work, and which review path applies.
The naming matters. These controls exist to keep the main assistant from loading the world. They return bounded context and routing pointers, then stop.
I also added context-loader as a combined pre-routing helper. It loads the memory and capability context contracts, returns a packet with separate memory context, capability context, routing hints, and unknowns, and leaves the final decision to the main agent.
Retrieval should stay advisory. Main remains the routing judge.
I made context loading a cheaper-model job. It needs to find the right files, exclude nearby but wrong ones, and return a bounded packet. Final judgment stays with the main agent or the appropriate analysis lane. That keeps the architecture more sustainable: spend less on retrieval and reserve stronger reasoning for tasks where judgment, synthesis, or risk justifies it.
Capabilities Hold the Real Workflows
The task procedures moved into capabilities/.
That includes search, memory governance, scheduled-job resilience, daily reports, market-confidence monitoring, portfolio monitors, email writing, media relay, large-artifact analysis, Git push handling, Hugo deployment, and other workflows.
These capabilities are loaded only when needed.
They sit behind a registry in CAPABILITIES.md. When a task calls for one, context-loader or the main agent identifies the relevant capability, then the main agent reads that specific file before acting.
This makes the system quieter.
Search instructions stay out of a branding edit. Portfolio monitor rules stay out of a Hugo post. Deployment rules stay out of a memory governance task. Memory deletion rules appear only when the task is actually about memory governance.
The shape is now clearer:
- Skills are front-door controls.
- Capabilities are task workflows.
- Methodologies are reusable thinking frameworks.
- State files are live facts.
- Owner files are authority.
Once I separated those layers, the assistant became easier to steer. The improvement came from the instance: it stopped throwing the whole toolbox into every turn.
Execution Lanes Separate Risk
The open-source runtime can run agents. My instance defines what each lane is allowed to mean.
I use different lanes for different work:
general-analystfor planning, review, research, and judgment-heavy work.general-execfor bounded read-only commands, scans, inventories, validation, and summaries.general-writefor bounded non-code mutations, such as docs, state, config, and reports.- Coding lanes for code architecture, implementation, and checks.
The distinction is based on risk type.
Read-only work, write work, code mutation, planning, implementation, verification, and synthesis all carry different failure modes. The architecture keeps those differences visible.
The strictest gate is code. Main and generic execution lanes must not mutate code/. Code changes go through coding implementation, then checks.
This is another instance-level decision. The base runtime can expose filesystem tools. My instance decides when access becomes permission.
That is how a personal agent avoids becoming one large shell with a friendly voice.
The lanes also let me use different models for different kinds of work.
A cheaper model can load context. A smaller execution model can run bounded inspections. A write-capable model can handle controlled non-code mutations. A stronger analysis lane can handle ambiguous judgment, research, and synthesis. Coding work can use a coding-oriented model with stricter implementation and verification gates.
That model split saves money, and it also matches model capability to task risk.
The expensive mistake is using one generic model lane for every kind of work and hoping instructions alone will create the right behavior.
Cron Jobs Became Runtime Components
My instance also has recurring jobs: memory hygiene, weekly memory governance, market-confidence monitoring, email heartbeat, portfolio jobs, stock re-underwrite workflows, daily reports, and model-shadow checks.
The easy version is to run prompts on a schedule.
I want recurring automation to behave more like infrastructure.
Scheduled jobs need state, delivery rules, retry discipline, idempotency thinking, report locations, and failure boundaries. Otherwise a cron job can fail halfway through a side effect and leave nobody sure whether the output is stale, duplicated, or partially applied.
So I pushed recurring work into owner files, scripts, reports, and state records. I added scheduled-job resilience as a capability. Agent calls get targeted retries for capacity and temporary overload. Whole-command retries require explicit idempotency or checkpoint safety.
This wiring is instance-specific. It turns recurring automation from timed prompts into operational components.
That matters more as the assistant touches more consequential workflows.
Safety Gates Are Instance Policy
OpenClaw can send messages, use tools, mutate files, push branches, and interact with external systems.
My instance decides when those actions are allowed.
Some actions require explicit approval or a standing exception: sending emails, posting publicly, sending out-of-band Telegram messages, mutating live cron or config, deleting files or memory, pushing branches, deployment, and anything that represents me externally.
Internal work can be bold. Read files. Inspect state. Draft. Analyze. Prepare. Validate.
External or destructive work changes the world outside the private workspace. That boundary belongs in the architecture as well as in the assistant’s tone.
This is why branch safety rules matter in the Hugo site. If I ask for a new branch, the assistant should create the feature branch, commit there, push only that branch, and avoid deployment unless I explicitly ask.
The system should make the cautious path the default path.
The Request Lifecycle in My Instance
A normal request now moves through a shaped path.
The Telegram message arrives with topic metadata. The main agent loads a small boot kernel. The workspace map resolves the topic. For non-trivial tasks, a cheaper context-loading lane retrieves bounded memory and capability pointers. The main agent chooses the route or lane. The relevant capability is loaded only if needed. A lane performs bounded work. The result returns to main. Main verifies, synthesizes, replies in the right place, and writes durable knowledge back to the correct owner file when needed.
That is the operating loop.
The model is one component inside it.
The architecture decides what context exists, which workflows are visible, which files own truth, which lane may act, what gets verified, and which actions need approval.
This is why my OpenClaw instance keeps improving even when the underlying model changes.
The leverage sits in the instance architecture around the model.
What the Open-Source Project Leaves Open
The open-source project leaves local ontology to the operator.
Its scope stops before my Telegram topic map, portfolio state ownership, Hugo workflow, code submodule defaults, memory governance boundaries, cron safety posture, writing preferences, and memory promotion rules.
Those things belong in my instance.
The framework provides primitives. The instance encodes local judgment. My architecture is the layer where local judgment becomes executable.
The Lesson
The main lesson from building my OpenClaw instance is that context is something to govern.
Too little context makes the assistant ignorant. Too much context makes it noisy. Stale context makes it worse: the model may follow a dead instruction confidently because it was still visible.
The useful middle is an architecture that decides what should be visible, when, and under whose authority.
That is why I moved most task workflows out of skills/ and into capabilities/. The system needed a smaller front door, a better registry, and a disciplined loading path.
OpenClaw gave me the substrate. My instance turns it into a working operating layer by making the environment around the assistant legible: topics, owner files, state, capabilities, lanes, cron, and gates.
That is how the open-source runtime becomes my operating layer.